LLVMのGSoC 2020に採択された
表題の通りGSoC 2020にProposalが採択されました。
summerofcode.withgoogle.com
Applyするに当たってたくさんの過去の参加者のブログを参考にさせていただいたので、僕も応募までに何をしたかを軽く記録しておきます。
Proposal
最終的に提出したProposalがこちらです(大した個人情報は載ってないのでそのままです)
docs.google.com
2月末
今年のOrganizationが発表される前に去年のをある程度眺めておきました。深く知っていたりよく使うOSSがあまりないのでどうしようかなぁと思って迷っていました。
2月にしたのはそれくらいで、2月末のCPU実験の最終発表をとりあえず頑張ろうと思ってコンパイラを頑張って書いていました
3月頭
CPU実験の影響もあって実際の大きなコンパイラの最適化に興味が出てきたのでGNUやLLVMのOpen projectのページを眺めました。GNUの方はRequirementにbe familiar with (よくわからん何か)とほとんどのものに書いてあったので諦めました。そしてLLVMのプロジェクトの一つにあった"Improve inter-procedural analyses and optimizations"が、自分の興味にもマッチしていたし、desirable skillsも大丈夫そうだったのでそれを選ぶことにして、メンター候補の方にメールを送りました。Preparation resourceの動画を見るも英語があまり聞き取れずに頭を抱えていましたが何回も見返したり去年のGSoCで動画の内容に関連する部分を実装されていた18erのuenokuさんの記事に大きく助けられたりしながらプロジェクトの内容把握につとめていました。uenoku.hatenablog.com
3月中頃
貧弱なマシンしか持っていないので学科PCで環境構築したり、パッチを当てたりしていました。今年は応募者が多いという話を聞いたりして多分無理なんやろなぁと思いながら作業してた気がします。
3月終盤
Proposalを書いていました。選んだプロジェクトはかなりふわっとしているので詳細を自分で詰める必要があり大変でした(それが普通かも)。既存のテストを眺めまくって現状を把握したりメンターとメールで相談したりしながら1週間くらいで書き上げました。Grammarly Premiumは最高です。
意気込み的何か
正直今まで経験したことないくらい不安です(メンターとの英会話とかも含めて)
演習3,ICPC,院試...といくらでも破滅要素があるのでなんとか完走できるように頑張りたいです。
理学部情報科学科3A
3Aの振り返りメモです、20erの方の参考になれば幸いです。 3Sについてはこちらをご覧ください理学部情報科学科3S - okura diary
対象読者誰?みたいな内容になってますがただのメモなのでご了承ください。
3Aの概観
準必修で先取りできるものもなく、基本的には皆必修のみです。課題との向き合い方次第*1で楽もできる(他のことに時間をまわせる)し忙しくもできるのかなと感じました。CPU実験がメインでそればっかりに集中できると思ってたらそうでもなく、他の課題も結構多いのでそれを片付けているとCPU実験に回せる時間もそこまで多くはない、というのが学期が始まる前に抱いていたイメージとの一番大きなギャップでした。
各授業の詳細
月2 言語モデル論
未だに言語モデルという言葉の指すものはよくわからないですが、3Sの言語処理系論の続きとなる授業です。言語処理系論がコンパイラなどプログラミング言語のsyntaxの部分を主に扱っていたのに対してsemanticsを主に扱う授業と言っても良い気がします。意味論には大きく分けて
- 操作的意味論
- 表示的意味論
- 公理的意味論
がありますが、この授業の前半ではインストラクションと評価文脈による操作的意味論の定義、ホーア論理(公理的意味論の一つ)による(半)自動プログラム検証の2つが重点的に取扱われます。表示的意味論は1回の授業でさらっと扱われるにとどまります(これは3Sに不動点演算子で再帰関数を書き換える課題などををやっているからだと思います)。 後半ではラムダ計算や型システムなど関数型言語に関連する話題を扱います。これは3SのFL実験の内容と重複して復習となる部分も多いです。
月4 連続系アルゴリズム
講義タイトルの通り連続量の問題を機械で解くためのアルゴリズム類を扱う授業です。 sd先生とysmt先生の2人が担当されていて、sd先生は主に常微分方程式、偏微分方程式の数値解法を、ysmt先生は主に行列の分解やCG法など多変数連立一次方程式の解法をそれぞれ主に扱っていた印象です。
sd先生パート
まず浮動小数の誤差評価の話から始まって、次にNewton法や減速Newton法など零点を求める方法を扱います。ホモトピー法笑 次に常微分方程式の解法として、Euler法、Runge-Kutta法をやってそのあと移流方程式や拡散方程式を差分法で解きます。ポアソン方程式を差分法で離散化すると大規模疎行列が係数の線形方程式になってysmt先生パートで学ぶ方法が使えるというのは面白かったです。これら以外にもFFTや加速、乱数なども扱われます。(結局加速って何やったんや...?)
ほとんどの課題で「方程式の数値解を描画せよ」という要件があるのでだいたいの人はPythonでMatplotlibを使っていました。自分は初めはPython書きたくないしモジュールの使い方を調べるのが面倒だったのでC++でファイル出力してgnuplotで描画してたのですが、あまりに面倒なのでmatplotlibに変えました。後述する知能システム論でも同様に描画を要求され、1セメスター通して使い続けることになるのでsubplotとかの使い方も早い内に慣れてしまうのがいいと思います(もう忘れてしまいましたが...)
ysmt先生パート
普通に掃き出し法で連立一次方程式を解くところから始まって、LU分解などの直接法をやった後、CG法、Gauss-Seidel法、SOR法などの反復解法を扱います。 他に冪乗法、Jacobi法で固有値を求めたり、Householder変換で三重対角化したり、特異値分解したりします
火2 計算量理論
タイトルの通り計算量についての授業です。決定性、非決定性チューリングマシンの定義から始まって、SATのNP-completeness(Cook-Levinの定理)を説明して、KarpのReductionでいくつかの問題がNP-completeであることを示します。 NP-completeな問題に対する解法として近似アルゴリズムを扱い、Metric-TSPに対する定数近似アルゴリズムやKnapsack問題に対してPTAS(Polynomial-Time Approximation Scheme)、FPTASを構成したりします。(この前のHash CodeのpracticeのKnapsackは貪欲とDPを適当に組み合わせたら全部入ったのでScalingとかが活用できなくて悲しかった)
火3,4,5 CPU実験(プロセッサ実験)
これに関しては別記事にまとめたのでこちらをご覧ください。
僕の呼びかけで、進捗発表が終わった後にCodeforcesのバーチャルコンテストを集まった人でやっていました。声をかけても人集まらないかなと思ってたのですが7人くらい集まったので3Sからやっておけばよかったと後悔しています。
水2 コンピュータネットワーク
A1タームのみの授業で、TCP/IPの基礎的な内容を一通り学びます。
木2 知能システム論
大きく分けて確率と統計の基礎、教師あり学習、教師なし学習、強化学習、自然言語処理を扱います。連続系アルゴリズムと同様に何度もビジュアライズを要求される課題が出ます。数学的に細かいところまでを教えてもらえるわけではないので、ちゃんと理解できてないけど書いてあるとおりにやったらなんかうまい感じにできてしまったみたいなことがありました(主成分分析やサポートベクトルマシンの課題とか)。カーネルトリックとか未だによくわかっていないので4Sで統計的機械学習を履修するなら要復習という感じがしています。
木3,4,5 コンパイラ実験
MinCamlというOCamlのサブセットのコンパイラを題材にコンパイラの基礎的な構成や最適化について学ぶ演習です。
前半
前半では既にMinCamlで実装されているK正規化、α変換、クロージャ変換、仮想マシンコード生成、レジスタ割付、機械語生成などの流れの詳細について理解します。
課題では別の変換を実装したり、より効率的と考えられる実装法を試して比較検討を行うといったものが多いです。(構文解析、型検査に関しては3SのFL実験と同じなので触れられません)
後半
後半では型多相、グラフ彩色によるレジスタ割当、データフロー解析、ループ最適化、JIT、GCなどMinCamlに限らずにより一般的なコンパイラの技術について学びます。
課題では既存の処理系での実装の詳細を調べたり論文を読んで説明させる説明系と、上に挙げた機能をMinCaml(もしくは自身がフルスクラッチしたコンパイラ)に追加する実装系があります。実装系課題はかなり重い傾向にあり、コンパイラ係以外で実装系課題をやっている人を見かけた記憶があまりありません。自分はコンパイラ係になったんやから課題は全部やろう、と思っていましたが実装系課題は締め切りに間に合わずできなかったものが多かったです。
課題について
3SのFL実験では実装系ではだいたい実装方針のお手本のようなものがあるのですが、この授業ではそういったものがありません。なので自分で考えた方針で実装するのですが、自分の方法が本当にいかなるソースコードが入力のときもそのプログラムの意味を変えないものであるのかを証明する手段がなく、なんとなくいくつかサンプルを作ってそれが動いたからOKとするしかないモヤモヤ感のなか課題を進めていたのを覚えています。できれば課題の期限終了後にお手本実装や想定解法を教えていただきたかったなぁという思いがあります。(実際にできたと言っている人に壊れる入力を与えたりして遊んでいました、被害を受けた方達ごめんなさい)
金2 科学英語
Wright先生の授業を選んでハンバーガーを食べると2単位がもらえます(注:これは必修ではありません)
金3,4 情報科学演習II
3Sの演習Iと同様に計算量理論演習と連続系アルゴリズム演習が隔週であります。
計算量理論演習
離散数学演習同様に計算量理論の授業と進度的にリンクしているわけではないですが内容的には同様です。各問題に点数がついていて低い配点の問題がなかなか解けないとつらい気持ちになることもありますが、全体を通じていくつか典型テクみたいなの(時間を犠牲にして空間を減らす、とりあえずSATで代表させてみる等)が見えてくると結構な問題を気持ちよく解くことができるように感じました。
連続系演習
こちらは基本的に授業で扱った方法の実装、評価が主な課題です。ですが授業の方でsd先生が出す課題と被っている部分がかなりあるのでそちらを先にちゃんとやっていればとても楽に済ませることができます。また完全に連続系の授業の内容のみではなく、授業で扱わなかったがこちらで扱ったトピックとしてはMPIによる並列計算やCUDAの利用などがありました。
その他
まとめっぽい内容が思いつかないので雑多なことを書きます。僕はほとんど旅行に行ったことがないタイプ(?)の人間なんですが、学期中に同期の友人*2に誘われて温泉地でまったりする楽しみを覚えてしまいました。スマブラが操作方法すらわからないところからみんなでワイワイできる程度になりました。あとハイパーロボットが多少うまくなった気がします。
まとめ
まぁがんばったのでOKです
*1:3Sはどの課題もここまでは必須、これはオプショナルといった形のものが多いのに対して3Aはこの階層構造が更に複雑になっています。 例えばコンパイラ実験は12回の内6回以上提出が必要、12回それぞれが次のn問の内m問以上を解答せよという形式(連続系演習も同様)、連続系の授業課題は課題がそもそもオプショナルでその中にオプショナル1とオプショナル2がある、といった感じです。授業のとある回の課題の提出を丸々しない、というのがどうも違和感があって結局どの授業のどの回も少なくとも提出要件を満たす分だけはやって出すようにしていましたが、もともとシステムがこうなっている以上面倒な課題は飛ばして別のことに時間を充てるのが得策ではあると思います。
*2:彼がスイスに行ってしまって寂しい
CPU実験の振り返り (コンパイラ係目線)
昨日CPU実験の最終発表会があり、無事CPU実験を終えることができました。このエントリはその振り返り、感想、ポエムです。 やった内容をつらつらと書いているだけなので真ん中のほうは面白くないと思うので細かい内容に興味無い方は読み飛ばし推奨です。 細かい内容が20er以降の方の参考になれば幸いです。
CPU実験について調べて到達した方は同期のコア係のMisterのブログ、同じくコア係のつばめの余興ブログ(僕が記事をまとめるのも恥ずかしいくらい彼が成し遂げたことはすごいです)もいっしょにご参照ください。
CPU実験の概要
CPU実験は東大理情(東京大学理学部情報科学科)名物と言われることの多い実験で、下の表にある4つの係からなる班を組んで自作コア上で与えられたレイトレーシング *1のプログラムを動作させることを目標にします。 アーキテクチャ等なんでも自分たちで好きなように決めてよい、FPGAボードが配布されるだけでなんの指示もないので自分たちで計画したり勉強しながら進めていく、といったあたりが特徴的な実験だと思います。ちなみに発表会で来年から素材がレイトレでなくなるかも、と教授が仰っていました。
| 係 | 仕事 |
|---|---|
| コア | Verilogでコアを書きます |
| OCamlのサブセットであるMinCamlという関数型言語で書かれたレイトレーシングのプログラムを自班のアーキテクチャをターゲットにコンパイルします | |
| コンパイラ係が吐いたアセンブリをバイナリにするアセンブラを書いたり、コア係やコンパイラ係がデバッグに用いるためのシミュレータを書きます | |
| FPU | VerilogでFPUを書きます |
コンパイラ係についてもう少し詳しく
コンパイラ実験のほうは基本となるMinCamlコンパイラを改造していく形で進んでいくのでこちらの実験もその形で進めていくコンパイラ係が多いですが、2ndあたりから好きな言語でフルスクラッチする人もいます(今年はGo,Haskell,Scalaでフルスクラッチしている人がいました)。僕はC++,OCamlくらいしか書き慣れている言語がない、パターンマッチとかがないのでC++は流石に面倒、という理由で最後までOCamlのままでした。
結果
やったことの詳細などの前に最終結果を記しておくと、総命令数14.18億(akouryyが10.8億で大差で1位)で2位でしたが、コア係*2の爆速コアのおかげで実機で111MHz,16.531秒の19er内最速記録を出すことができました。一応速さコンテスト的側面もある実験なので嬉しかったです。
やったこと
ここからは僕がやったことを時系列順に書いておきます
9,10月
まず初回授業で係を決めました、僕は仕事内容的にはコア係かコンパイラ係をやりたいと思っていたのですが、3Sのハードウェア実験でVerilog,Vivadoに対して苦手意識をもってしまったので半ば消去法的にコンパイラ係を希望しました。班が決まったら、まず1stのISAを決めたり(ぼーっとしていたらいつのまにかMIPSベースにすることが決まっていました)、これからの計画についてなどを話しあいました。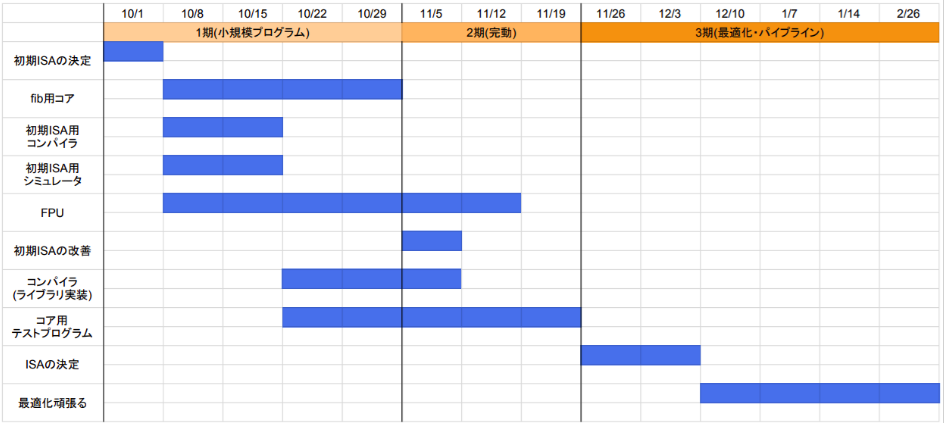
1週目
初週はコアのデバッグのためにも、フィボナッチなどの簡単なプログラムのアセンブリをなるべくはやく生成したいと思い、PowerPC向けのMinCamlコンパイラのemitを変更して自班アーキテクチャ(以下Nikujaga)向けに改造することに専念しました。データセクションなどを用意していないので浮動小数即値テーブルの作成などを変更しました。
2週目
2週目はレイトレをコンパイルすることに専念しました。レイトレを動かすにはいくつかのライブラリ関数(sin,cos,atan,sqrt,floor,ftoi,itof,etc.)が必要なのですが、これらを実装するのも通常コンパイラ係の仕事です。とりあえずはやく動かしたいと思ったのでライブラリ関数は初めは精度を無視して適当に書きました。コンパイルできたと思ったらシミュレータで動かすと永遠に処理が終わらなくてその原因特定に時間を溶かしたりしました(結局自分が書いたライブラリ関数の二分探索が無限ループしていた。画像サイズを2×2とかにしてみても中々実行が終わらないときはほぼ間違いなく何かが無限ループしていると思います)。
3週目
もうすぐコアができそうと連絡があったので「全班内最速で10月中に完動させよう」ということでライブラリの精度を規定を満たすように精度を上げたりしていました。その後コアが出来上がったもののレイトレが動かなかったのでコア係がデバッグしているのを横で応援したりしていました。
11,12月
10月中という目標には間に合いませんでしたが11/5に一番早く完動させることができました。これで一段落ついたのでここからは最適化を頑張るフェーズに入ります。
グローバル変数の導入
レイトレのプログラムは先頭で定義される配列を後ろの関数群がなんども読み書きするような構造になっているので、ほとんどの関数に自由変数があり関数呼び出しはクロージャを介したものになります。そこで初めて関数が定義されるまでに定義される変数たちをグローバル変数として扱うことでオーバーヘッドの大きいクロージャ呼び出しをなくすことができます(これはレイトレのソースの特性上そうなるということです)。具体的には配列やタプルのアドレスをコンパイル時に確定しておいて、それ以降でのアクセスではメモリの定数番地に対するアクセスとして処理するようにします。
覗き穴最適化
特定の命令パターンを等価でより効率的な命令パターンに置き換える最適化です。この最適化パターンのほとんどは自分のコンパイラが吐いたアセンブリを眺めて無駄だなと思ったものを随時追加していきました。別の最適化をかけることではじめて見えてくるパターンもあり2月まで少しずつ増えていきました。
定数畳み込み
仮想マシンコードレベルでの定数畳み込みを実装しました。より前段階の中間表現でも定数畳み込みは行われていますがグローバル配列アドレスが即値に変わっていたりすることで仮想マシンコードでも定数畳み込みが効きます。
不要定義削除
定数畳み込み同様に前段階で行われていますが、仮想マシンコードレベルで再度不要定義削除を行いました。タプルを分解してそのうちいくつかしか使わないと使わなかった変数のロードが無駄に残るのでそういったものが消えます。
これを実装したところレイトレが壊れてしまったのですが何度実装を見直しても原因がわからないしシミュレータで実行してみてもどこが悪いのか見当をつけることが難しく結局導入に3週間近くかかりました。原因は覗き穴最適化が間違っていたからで、不要定義削除自体はバグっていませんでした。
このようにバグった覗き穴最適化だけしてもレイトレは運良くバグらないが、さらに不要定義削除をするとそのバグが顕在化するいうこともあるので最適化は全てモジュールごとに切り分けてバグった際は色んな組み合わせで最適化のオンオフを試してバグの原因である最適化を特定する、ということが有効かもしれません。
2ndへ
ソフトウェア実装していたsqrt,floor,ftoi,itofをFPUが実装してくれることになったので、これらを加えたISAを2ndとしました。この頃に追加命令をMLソースから直接触るためにAsmキーワードを追加してインラインアセンブリ風に書けるようにMinCamlの構文を拡張したりしました。
1,2月
1月のテスト後はコンパイラ係向け課題も兼ねてレジスタ割当の改善に時間を費やしました。
制御フローグラフ作成,生存解析,干渉グラフ作成,グラフ彩色
3Sの言語処理系論のスライドやタイガー本などを読んで設計を考えてから実装をしました干渉グラフの実装をしようとしたあたりからocamlgraphというライブラリを見つけたのでそれを利用しました。ドキュメントが少なくて使い方が若干難しいですが色んなモジュールが備わっていて便利でした。

3rdへ
2月末にコア係がコアを書き直すというので3rd ISAで自分の希望する命令を足してもらいました。ずっとやった最適化が他班より多くてもその班より命令数が多いのはなんでやと頭を抱えていたのですがISAの違いはかなり大きいことがわかりました。1st,2ndのMIPSベースのISAでは分岐命令が貧弱でBranch EQual、Branch Not Equelしかなかったので、2つのレジスタの大小を比較して分岐する際は一旦Set Less Than命令でレジスタに値をセットして、ゼロレジスタと比較して分岐するようになっていました。そこでBranch Less Than命令などを追加してもらいました。他にはデータを扱う際は全てワード単位なので、バイトアドレシングからワードアドレシングへの変更も行いました。
Coalescing
レジスタ割当後のmove命令がなるべく減るようにcoalescingを実装し、実際にmov命令が削減されましたが結局元のレジスタ割当より命令数が減りませんでした。減ったと言っている人も何人かいたので自分の実装が悪かったようです。
余ったレジスタの定数レジスタ化
まずゼロレジスタを有効活用するような最適化をかけるとだいぶ命令数が減ったのでレジスタ割付で使われないレジスタを全てプログラム中にある定数の定数レジスタにして定数をロードしてから演算しているところを定数レジスタと演算させるようにしました。
ジャンプの連鎖の除去
ジャンプしてその先ですぐに無条件ジャンプするときは初めからジャンプ先をそこにしておいたほうが得なのでその最適化をしました。最終発表会の前日にやったのですが3000万命令も減って驚きました。
スケジューリング
アセンブリを見ると浮動小数演算してその結果をすぐ次の命令で使う、という部分が多くストールが起こりそうなところが多かったのでコア係と一緒にアセンブリをながめてこういうパターンはこう置き換えようという議論をしてから実装しました。この命令パターンで何clk分ストールするかというのは僕にはわからないことなのでコア係との初めての共同作業でした。スケジューリングで命令数は据え置きで0.3秒も早くなったので驚きました。これは発表会当日の朝地下でやったのですが「もっと協力するべきやったな〜」って言い合ってました(遅い)。
発表会3日前の時点で19.98秒とかだったのですが色々あって当日の朝までに16.53秒まで持っていくことができました。
反省点、教訓など
Verilogを触りたくないあまりコンパイラ係を志望してしまったので逃げずにコア係やってみるのも良かったのかなぁと未だに思ったりします。20er以降の皆さんは積極的理由で係を選ぶと良い気がします。
データフロー解析による不要命令削除や共通部分式削除、値番号付け、エイリアス解析、タプル平坦化など、時間さえあればやれることはまだまだできることはあったなという思いがあります。
コードレビューとかがなく実質個人開発でスパゲッティソースになりがちで、もっと綺麗にしたいなぁというところが最終状態のコンパイラにも大量にあります。リファクタリングを頻繁にすると良いと思います。
あとで変えようと思って変え忘れる、コピペして変え忘れる、が本当に多かったので少なくとも前者は変えようと思った時点でその場にコメントでtodoを記しておいてpush前にtodoコメントが残っていないかチェックする、という習慣をつければよかったなぁと後悔しています。(つばめがこの習慣を実践しているのを教えてくれた、自分の記憶力を信じてはいけません、忘れます)
コンパイラ係はシミュレータ係に欲しいと思った機能はどんどん実装をお願いしてしまいましょう。途中からコア係の要請で指定命令数だけ実行する機能がついたのですが、それまで自分はバグの場所の二分探索をする時にブレークポイントをかけてそこまでの実行命令数見て...みたいな非効率なことをしてたので自分からお願いするべきだったなぁと感じました。
シミュレータにはアセンブリがinvalidでないかしっかりチェックしてもらうようにしましょう。コンパイラは(なるべくassertをいろんなところにかけてチェックするようにはしているのですが)ちょっといじるとすぐinvalidな命令を吐くようにしてしまいます。例えばレジスタのオペランドがよくわからない文字列になっていたり、符号付き16ビットの即値に範囲外の値が入っていたり、ということがあります。そういうときによしなに解釈されて実行されているとバグフィックスに時間がかなりかかってしまうと思います。
またシミュレータの話になるのですが、シミュレータがメモリリークしており、何度も起動しているうちにパソコンがめちゃくちゃ重くなるということがあったのでC,C++で書かれているならビルドのときに
-fsanitize=addressなどのsanitizerで未定義動作やメモリリークをチェックしておくと安全かもしれません。
感想、その他
つらつらとやったことを書きましたが、20er以降の方には是非ここに書いた程度の最適化はササッと終わらせて歴代最高記録(たしか8.何億命令と聞きました)を越えるような最強コンパイラを作って欲しいないう思いがあります。
初めはコンパイラは意味が変わらないようにアセンブリに落とすだけ、最適化も意味が変わらないように変換していくだけやん、と少し思っていましたが、ちょっと触るだけで本当に面白いくらいバグるのでコンパイラに対するイメージはだいぶ変わりました。普段よくつかう言語処理系を開発してる人たちってすごいんやなぁと今はとても感じています。
何はともあれ無事に終わってよかったです、班員のみなさん、19erのみなさんお疲れ様でした。
Wavelet MatrixとFM-index
この記事はISer Advent Calendar 2019の1日目として書かれました。
最近ライブラリの剪定をしているときに「そういえばWavelet Matrix実装してないなぁ」と思ったので実装してみたら想像以上にシンプルで驚いたのでそれについての軽い解説を書きました。競プロ方面への応用については色んな方が記事を書いているので、後半ではWavelet Matrixの全文検索への応用としてFM-indexの話をします。
Wavelet Matrixとは
データ構造を知る時に最も衝撃を受ける瞬間はどういう操作がどんなオーダーでできるか知る時ですよね。なのでWavelet Matrixができる操作をまずは紹介します。 静的な文字列(数列)Sに対して以下のようなクエリに高速に(具体的にはアルファベット集合の大きさの対数時間)答えられるようなデータ構造です。(動的にもできますがここでは静的な場合を扱います。)
| クエリ名 | 操作 |
|---|---|
| access(i) | S[i] |
| rank(c,i) | S[0,i)中の文字cの数 |
| select(c,i) | Sのi番目(0-indexed)のcの場所 |
| kthMax(l,r,k) | S[l,r)でk番目に大きい文字 |
| rangefreq(l,r,low,high) | S[l,r)のlow以上high未満の文字の数 |
| prevvalue(l,r,low,high) | S[l,r)でhigh未満low以上を満たす文字で最大のもの(すなわちhighのprev value) |
| topk(l,r,k) | S[l,r)で出現回数が多い文字k個を頻度とともに返す |
この表だけでも色んなことができる感じがしますね。この表のクエリ以外にも高速に処理できる操作はたくさんあります。例えばkthMaxを用いれば任意の区間の中央値を高速に求めることができますし、topkを用いれば区間の最頻値も簡単に求まります。 次の章からWavelet Matrixの説明をしていますがかなり端折った説明なのでここやここのスライドを見たほうが絶対にわかりやすいと思います。
Wavelet Tree
Wavelet Matrixと同等の時間計算量で同じタイプのクエリを処理できるデータ構造にWavelet Treeがあります。こちらのほうが視覚的にわかりやすいのでまずこちらのイメージをつかんでからWavelet Matrixの説明をすることにします。
Wavelet Treeでは文字列(数列)の値を上位bitから順に0か1かで分類していきます。例として[0,8)の区間の値からなる数列
7232514067125137を例に用います。各bitが0ならば左へ、1ならば右へ値を移動することにすると各段階で数列は下のようになります。
7232514067125137 (3bit目で分類) 2321012137546757 (2bit目で分類) 1011232235457677 (1bit目で分類) 0111222334556777
二分木の構造が見えやすいように間をあけると下のようになります。
7232514067125137 (3bit目で分類) 232101213 7546757 (2bit目で分類) 1011 23223 545 7677 (1bit目で分類) 0 111 222 33 4 55 6 777
Wavelet Treeではこの木の情報を上のような値を直接管理するのではなく各数字が左に行ったか(着目するbitが0だったか)右に行ったかを01で表すことによって保持します。例では以下のようになります。
1000101011001001 1110001011001101 1011010011011011
この01だけから1段下の対応する位置はどうやって求めればよいかを考えてみます。0,1それぞれの場合で、自分より前の0と1が何個あるかがわかれば、行き先のノードのどのインデックスが自分に対応しているかがわかります。例えば、例において添字2(0-indexed)の3は3bit目で分類したあと左の子の添字1に対応する位置に来ますが、これは自分より前に0が1つあることからわかります。
完備辞書(簡潔ビットベクトル)
先程述べたような自分より前の0,1の数を数える、x番目の0,1の添字を求める、といった操作を定数時間で実現するデータ構造が完備辞書です。完備辞書の機能自体は簡単に別の方法で実装できますが、完備辞書は簡潔データ構造と呼ばれるものの一つでその機能を省メモリで実現できることが特徴です。これについての解説はMisterが去年記事を書いてくれているのでこちらに丸投げしようと思います。(投げやり)
重要なことは元データのbit数の線形オーダーのbit数の補助データでビットベクトルのrank,selectが実現できるということです。
Wavelet Treeの計算量
文字列のアルファベットの集合の大きさをとします。Wavelet Treeではほとんどのクエリは木の深さのオーダーで処理することができ、
となります。Wavelet Treeの問題点は空間計算量です。ビット列に
,補助データに
,そして木のポインタに
必要になります。しかし
が非常に大きくなるとポインタに必要な空間がネックになってきます。このポインタをなくし、木を辿りながら対応する区間のインデックスを計算するようにしたのがWavelet Matrixです。(Segment Treeにおいて左右の子を2k+1,2k+2とする実装のようなイメージ)
Wavelet Matrix
Wavelet MatrixではWavelet Treeの時と同様に各bitで値を左右に振り分けていきますが、Wavelet Treeでは木構造がそのまま見えます(すなわち2つの部分木の境界を上のような図上で線で引いて表現できる)が、Wavelet Matrixでは各深さのノードの順序が入れ替わっておりその木構造がパッとは見えません。先程と同様に例を通して見てみることにします。 各深さにおいて着目するbitが0ならば左1ならば右へ移動するのは変わりませんが、より前の深さでの分類を考えずにWavelet Treeにおける1段目かのようにデータを移動します。
7232514067125137 (3bit目で分類) 2321012137546757 (2bit目で分類) 2322376771011545 (1bit目で分類) 3311155777022264
データの動きとしては基数ソートに似ていますね(基数ソートとの違いは下位bitから見るかどうかです)。実は上のデータ列にはWavelet Treeの場合の各ノードに対応する連続区間があります。それがわかりやすいように空白を入れたものが以下です。
7232514067125137 (3bit目で分類) 232101213 7546757 (2bit目で分類) 23223 7677 1011 545 (1bit目で分類) 33 111 55 777 0 222 6 4
Wavelet Treeの場合の例と見比べると順番は違いますが確かにノードが存在しています(存在は簡単に示せます)。では7546757に対応する頂点から左の子である7677に移動する、といった操作を具体的にどのように計算すればよいかを考えてみることにします。(区間のインデックスから左右の子に対応するインデックスが計算できることでポインタが不要となるのでした)
Wavelet Matrixにおいても以下のようにWavelet Treeと同様に上の例のようなデータを各値が左右どちらに行ったかの01の列として保持します。そして補助データとして各深さにおいて0がいくつあるか(zeroNum)も保持しておきます。
1000101011001001 (zeroNum: 9) 0001110100110010 (zeroNum: 9) 1011001000100010 (zeroNum: 10)
少し考えれば、深さdの[l,r)に対応する頂点の左の子は深さdの列における[rank(0,l),rank(0,r)),右の子は[zeroNum[d]+rank(1,l),zeroNum[d]+rank(1,r))であることがわかります。この式の形からこの計算も完備辞書を用いれば定数時間でできることがわかります。これで頂点のポインタを持たずにWavelet Treeと同等のことができることがわかりました。
各クエリの実装
以上でWavelet Matrixの構築は終わりです。あとは構築したデータを使ってクエリに答えていきます。各クエリはこの木上を辿ったり探索することで木の深さのオーダーで処理することができます。実際の細かい手順は先程のリンクのスライドで丁寧に説明されているので今回は詳細な説明は省きますが、実装してみると理解が深まると思います。自分はaccess,rank,select,kth-max(quantile),rangefreq,prevvalue,nextvalueあたりを実装しました。この後紹介するFM-indexの実装もここにあります。
FM-indexとは
ここからはせっかく作ったWavelet Matrixを使って何かしてみようというお話です。
Suffix Array
文字列検索には様々なアルゴリズムがありますがSuffix Array(接尾辞配列)を構築して二分探索することで長さnの文章Sから長さmのパターンTをで求めるアルゴリズムがあります。Suffix Arrayというのは接尾辞(その開始インデックスで表す)を辞書順にソートした列で、例えば"abracadabra"という文字列に対しては以下のようになります
i sa[i] 0 11 (空文字列) 1 10 a 2 7 abra 3 0 abracadabra 4 3 acadabra 5 5 adabra 6 8 bra 7 1 bracadabra 8 4 cadabra 9 6 dabra 10 9 ra 11 2 racadabra
Suffix Arrayの構築は愚直に計算して,ダブリングを用いる方法で
,みんな大好きSA-ISで
でできることは有名ですが、今回はここには深入りしないことにします。接尾辞でソートされているので、検索パターンを接頭辞に持つような接尾辞はSuffix Array上で連続しており、この区間は二分探索によって求めることができます。例えば上の例で"bra"を接頭辞に持つような接尾辞はSuffix Arrayの[6,8)に対応しており、これからSのsa[6]=8文字目と、sa[7]=1文字目からの3文字が"bra"であることがわかります。この二分探索の計算量は1回の文字列比較に
,比較を
回行うので
となります。
FM-indexではこのSuffix Array上での区間を求める操作を
で実現します。
はアルファベットのサイズで、charの場合は256ですから、これを定数とみなせばパターンの長さの線形時間でできることになります。驚くべきは元の文字列の長さnに依存していないことです。非常に長い文章からパターンを検索する場合に力を発揮しそうですね。Wavelet Matrixを用いるための準備をいくつか行います。
Burrows Wheeler 変換
今後の準備のためにいくつか記号を定義します。sa[i]文字目からの接尾辞の初めの文字をSf[i]と呼ぶことにします(空文字列のときは(任意の文字より若い)ダミー文字とする)。 またC[c]をS中に含まれる文字cより小さい文字の数とします。(累積和で簡単に求まります) 文字列SのBurrows Wheeler変換BWTは以下のように定義されます。
bwt[i] = S[sa[i]-1] (sa[i]>0の時)
ダミー文字 (sa[i]=0の時)
上の例では
i bwt[i] sa[i] 0 a 11 (空文字列) 1 r 10 a 2 d 7 abra 3 $ 0 abracadabra 4 r 3 acadabra 5 c 5 adabra 6 a 8 bra 7 a 1 bracadabra 8 a 4 cadabra 9 a 6 dabra 10 b 9 ra 11 b 2 racadabra
となります。 BWTの直感的な意味は、S[i]を後続の接尾辞S[i+1,n)をキーとしてソートしたものです。 このBWTは定義より明らかにSfの各文字が1度ずつ現れます。したがってBWTはSfの順列と思うことができますが、BWTにはよい性質があり、BWTのみからSfを復元することができます。この復元をLF mappingと呼びます。
LF mapping
まずBWTの重要な性質として「各文字についてbtwにおける出現順とSfでの出現順は同じになる」というものがあります。 例えば上の例でaに番号をつけると、
i bwt[i] sa[i] 0 a5 11 (空文字列) 1 r 10 a5 2 d 7 a4bra5 3 $ 0 a1bra2ca3da4bra5 4 r 3 a2ca3da4bra5 5 c 5 a3da4bra5 6 a4 8 bra5 7 a1 1 bra2ca3da4bra5 8 a2 4 ca3da4bra5 9 a3 6 da4bra5 10 b 9 ra5 11 b 2 ra2ca3da4bra5
aはbwt,Sfのどちらでも5,4,1,2,3の順で現れていることがわかります。これが常に成り立つことが辞書順の定義からすこし考えれば示せます。
そして、Sfはソートした接尾辞の先頭文字なので当然ながら辞書順に並んでいます。この2つの性質を用いてBWTからSfを求める方法を考えてみることにします。
例えば上の例でa2 = bwt[8] = Sf[?]の?を求めたいとします。Sfは辞書順であったことからaよりも若い文字は全て?より前にあり、この文字数はC[a]=1(ダミー文字のみ)です。逆にaより大きい文字は?より前にありませんから、後は?より前にaがいくつあるかがわかれば良いです。この個数は先程述べた性質よりbwtで8より前にあるaの個数に一致します。やっとWavelet Matrixが使えそうな形が現れてきましたね。bwtからWavelet Matrixを構築すればこの値はrank(a,8)として計算できます。
rank(a,8)=3(a5,a4,a1の3つ)から?=3+1=4と求めることができます。確かにSf[4]=a2となっていることが上の例でも確認できます。ここまでの話を式にまとめると、
c=bwt[i]の時,Sf[rank(c,i)+C[c]]=bwt[i]となります。
FM-index
いよいよLF-mappingを用いて検索パターンTに対応するsaのインデックスの区間[l,r)を求めていきます。空文字列から初めて、T[m-1,m)に対応する範囲、T[m-2,m)に...,T[0,m)に対応する範囲というように更新していきます。空文字列は任意の文字列の接頭辞ですからl=0,r=n+1として初期化します。今T[i+1,m)に対応する区間[l,r)が求まっておりT[i,m)に対応する区間を求めようとしているとしましょう。[l,r)の中でbtw[idx]=T[i]となるようなidxにしか興味がありませんが、そのような最小のidxが存在するならrank(T[i],idx)+C[T[i]]=rank(T[i],l)+C[T[i]]、同様にそのような最大のidxについてもrank(T[i],idx+1)+C[T[i]]=rank(T[i],r)+C[T[i]]なので、
l = rank(T[i],l)+C[T[i]] r = rank(T[i],r)+C[T[i]]
とするだけでT[i,m)に対応する区間が求まります。
例で確認してみましょう。"abracadabra"から"bra"に対応する[6,8)を求めます。
(再掲) i bwt[i] sa[i] 0 a 11 (空文字列) 1 r 10 a 2 d 7 abra 3 $ 0 abracadabra 4 r 3 acadabra 5 c 5 adabra 6 a 8 bra 7 a 1 bracadabra 8 a 4 cadabra 9 a 6 dabra 10 b 9 ra 11 b 2 racadabra
l = 0, r = 12
[ ""に対応する区間は[0,12) ]
l = rank('a',0)+C['a'] = 0+1 = 1, r = rank('a',12)+C['a'] = 5+1 = 6
[ "a"に対応する区間は[1,6) ]
l = rank('r',1)+C['r'] = 0+10 = 10, r = rank('r',6)+C['r'] = 2+10 = 12
[ "ra"に対応する区間は[10,12) ]
l = rank('b',10)+C['b'] = 0+6 = 6, r = rank('b',12)+C['b'] = 2+6 = 8
[ "bra"に対応する区間は[6,8) ]
ちゃんと求まっていることが確認できますね。
実装
Suffix Array, Wavelet Matrix, Cにあたる配列の計算さえ実装してしまえばたった数行で書けてしまいます。
pair<int,int> searchFMIndex( SuffixArray &sa, WaveletMatrix<unsigned char,8> &wm, vector<int> &lessCount, string t){ int l = 0, r = sa.size()+1; // because of dummy character for(int i=0;i<t.size();i++){ unsigned char c = t[t.size()-1-i]; l = lessCount[c]+wm.rank(c,l); r = lessCount[c]+wm.rank(c,r); if(l>=r)return make_pair(-1,-1); } return make_pair(l,r-1); }
性能の比較
前にも述べたとおりFM-indexが、Suffix Array+二分探索が
なので長い文章から長めの文章を検索すれば差がつくかなと思って実験してみました。初めに100MBの圧縮技術とかのベンチマーク用text fileを落としてきてやろうとしたのですがどうやらメモリとりすぎで怒られてしまうようだったので5MBの聖書を何回かconcatしてギリギリのサイズの文字列を作って、適当な場所から10000000文字くらい取ってきたもので検索してみました。結果が以下です。
Length of the original text 32112346 Suffix array construction finished. Burrows Wheeler Transformation finished. Wavelet Matrix construction finished. Array C construction finished. Length of the pattern 10000000 [Wavelet Matrix] time: 22302.421999999999[ms] [Suffix Array] time: 8.371000000000[ms] [Wavelet Matrix Answer] 17540883,17540887 [Suffix Array Answer] 17540883,17540887 verdict : OK
!!!!!!FM-index遅!!!!!!!
感想
完備辞書の実装が悪いのかなにかわかりませんが色んな長さの文字列を検索してみても全部二分探索のほうが早くて笑いました。所詮log同士の戦いなので劇的に早くはならないのかなとは思っていたのですがここまでとは思いませんでした、定数って厳しいですね。
実はWavelet Matrixの実装は2Aの実験の課題にもなっていましたが簡潔ビットベクトルでちゃんと簡潔性をサボらない実装が面倒で当時はやめてしまいました。もやもやしていたので1年越しにちゃんと実装できてよかったです(結局簡潔性はある程度サボっていますが)。
苦手で避けがちだった文字列が最近個人的に楽しくなってきてPalindromic TreeとかSuffix Automatonの盆栽をそろそろしたいなという気持ちでいます。みなさんもデータ構造の盆栽しましょうね。
明日2日はHelloRuskさんの記事です、お楽しみに。
理学部情報科学科3S
書かないと記憶の彼方に消えてしまうと思うので簡単な振り返りメモです。
対象読者 : そこのあなた
後輩に有益かどうかはわかりません。2Aについては同期のブログ
kammer0820.hatenablog.comが詳しいです。
課題のネタバレなどはなるべくないように注意したつもりなのでご安心ください(?)
諸々の成果物は以下にあげてあります。
github.com
ネタバレ回避のためにバイナリのみです。(使い方のdocumentはそのうち整理したい)
- 月2 オペレーティングシステム
- 月3,4 システムプログラミング実験
- 火2 離散数学
- 火3,4 関数論理型プログラミング実験
- 水2 情報論理
- 木2 言語処理系論
- 木3,4 ハードウェア実験
- 金2 計算機構成論
- 金3,4 情報科学演習Ⅰ
- 課外
- まとめ
月2 オペレーティングシステム
講義名のとおりOSの仕事や仕組みを一通り学びました。
- プロセス管理、プロセス間通信
- CPUスケジューリング、リアルタイムスケジューリング
- メモリ管理(仮想記憶、ページングなど)
- I/Oシステム
- ファイルシステム、ディスクスケジューリング
などです。はじめの方はシスプロと連携が取れている感じになっていて、ここで学んだことをシスプロで実際に触ってみることが多かったですが途中からお互いに独自路線に走っていきます。
スライドの量が膨大な上に抽象的な図が多くて試験前に焦りますが試験はスケジューリングなどの計算問題がほとんどを占めるので無意味に暗記しなくても大丈夫です。試験は1問15分で解くことが想定されていて、試験時間が75分で、大問が6問でした(?)
月3,4 システムプログラミング実験
各週でやったことを順に書きます。
パソコンの常識みたいなのがある程度教えてもらえるので純粋培養競技プログラマーみたいな人でも安心です。このあたりでman pageを読みまくったり困ったらとりあえずstraceしてみることを覚えました
- マルチスレッドプログラミング
pthreadを使って遊びます。2分探索木をスレッドセーフに書き換えたり、Bounded bufferを書いたりします。
- ソケットプログラミング
UDP echo serverやTCP echo serverを書いたりネットワークのスループットを測ったりしました。マルチクライアントに対応するのにpthreadを用いるのは楽でしたがepollを使う方法は大変だった記憶があります。epollの仕様難しい。
- シェル作成
普段つかっているbashのようなものを作ります。2Aの計算機プログラミングで吉本先生が板書していたよくわからないforkのコードの意味がようやくわかりました。多段パイプやリダイレクト、fg,bgなどのジョブ管理を実装しました。プロセスごとにファイルディスクリプタの状況が違うとかを理解しておらずめっちゃハマりました。各々なにかしらに躓いたりテストスクリプト通らん!とか言いながら夜までみんなで実装するのは結構楽しかったです。
最後に完成版として提出したishは上げてあります。多分いじわるすると壊れます。
- カーネルプログラミング
linuxカーネルのコードを読んだり、システムコールを追加したりします。カーネルのコードがどこまでいってもマクロだらけでびっくりしました(小学生並みの感想)
- ベアメタルプログラミング
ベアメタルプログラムはOSに依存せずに自力でハードウェア上で動作するもののことで、OSに依存しないので下手をするとパソコンがぶっ壊れますが、
TAさんが準備してくださった環境のおかげで仮想マシン上の、ものはクラッシュしてもPC全体はクラッシュしないようになっていました
MMUの仕様を理解して指定された物理アドレスを指定された仮想アドレスにマッピングしたり、atomic命令を用いてspinlockを実装したり、タイマのレジスタを読みだしたりしました。
TAさんが準備してくださった環境のおかげで実装量がとても少なかったです。
NIC(Network Interface Controller)のドライバを書いて、パケットを送受信してMACアドレスを読み取ったり,ARP requestを受信してARP replyを送ったりしました。documentを読みまくりますが、結構わかりづらかったり似たような表だらけだったりで大変でした。
火2 離散数学
グラフ理論、線形計画、フロー、双対性、マトロイドなどを扱いました。個人的にはほぼ既知の内容でしたがいつも結果ばかり使っていて証明できるかは怪しかったのでよい復習になりました。
テストで行列を答案に写し間違えたりすると無駄な単体法を実行して終了するので注意しましょう!
火3,4 関数論理型プログラミング実験
主にOCamlとPrologを扱います。毎回レポートが100点満点で採点される1300点満点の競技です(違う)
- 序盤
OCamlの基礎的な文法や型の扱い、モジュールシステムやモナドなどを扱いました。モナド難しかったです。
- 中盤
OCamlでOCamlライクな関数型言語のインタプリタを作成します。序盤に比べてやればできる課題が多かった印象です。
最新verとして提出したOCamlインタプリタは上げてあります。
- 終盤
いきなり大きくかわって論理型言語としてPrologを扱います。SLD導出や閉世界仮説について学びました。最後にはPrologライクな言語のインタプリタを作成しました。
本筋とは関係ない単一化とかでめちゃくちゃバグらせて悲しかったですが最後は納得のいくインタプリタができたのでよかったです。こちらも上がってます。
- 最終課題
これまた打って変わってリバーシのAIを実装する課題がでました。これについては別記事で上げてあります(リバーシAIを実装した話 - okura diary)
水2 情報論理
大きく2つに分けるとLogicとComputabilityの授業です。LogicではEquational logic,Propositional logic,Predicate logicなどを扱い、それらの健全性、完全性などを学びました。別のformalismとしてResolutionを学んだりHerbrand's structureやSkolemizationも学びます。ComputabilityではPrimitive recursive functionから始まってrecursive function,while program,universal recursive functionなどを学び、それからSmn定理やrecursion theorem,Rice's theoremなどをやってからHaltがnot recursiveでrecursively enumerable(RE)なことやnot HaltがREでないことを示し、そして最後にGödel's incompleteness theoremを示す、という流れでした。前期教養の記号論理学では自然演繹を扱いますがこの授業ではシーケント計算(LK)を扱います。記号論理学よりもformalな内容で新鮮で面白かったし、蓮尾先生の教科書がとてもわかりやすく楽しかったです。
木2 言語処理系論
いわゆるコンパイラの授業です、コンパイラの流れにしたがって字句解析、構文解析、意味解析、中間コード生成、レジスタ割り付け、最適化などを一通り学びます。小林先生のスライドは各ステップが細かくのっているので後からみてもわかりやすいです。FLと内容が結構重複している上にFLで先にやることが多いの授業は気軽に聞けます。
試験には毎年LR(0)オートマトンやSLR構文解析表が出るのでたくさん書いてオートマトン職人になりましょう、あと二村射影が出ます[要出典]
木3,4 ハードウェア実験
はじめの方はブレッドボードで回路を作ったりします、どれだけ確認しても正しいのにうまく動かなくて、結果汎用ICが壊れてたことがありました(つらい)
途中からはvivadoをつかってFPGAで遊びます。IPコアを組み合わせて遊ぶ分には楽しいのですが、後半でSystem Verilogでモジュールを書く必要がでてきてからは全然テストを通ってくれなかったりして大変でした。具体的には浮動小数点加算(fadd)やUARTでの通信、AXI4バスの転送などをやりました。デバッグ方法が難しくて毎回長い時間溶けましたが班員に助けてもらいつつなんとか乗り越えてました。低レイヤーの厳しさを痛感しました。
金2 計算機構成論
コンピュータアーキテクチャの授業です。坂井先生が書かれた教科書(指定されている)がわかりやすくて、4月の1週目に全部読んでしまいました。簡単な模式図から始まって各ユニットがどんどん詳細になっていくのでとてもわかりやすいし視覚的にも楽しいです。途中にアーキテクチャから1つ選んで発表するという回があります。
内容としてはパイプライン、キャッシュ、仮想記憶、並列実行(複数命令発行、アウトオブオーダー実行など)などで、OSとかぶる部分が結構あります。
課外
- パタヘネゼミ
パタヘネの上下巻を読んで発表しあいました。OSや計算機構成論とかぶる部分が多いですがここで複数回触れていたおかげでより頭に定着したような気がします。
来年こそは...見とけよ。
まとめ
充実してたかどうかはわかりませんが、課題に追われたり地下や食堂で駄弁ったりいろいろ楽しかったのでOKです。
リバーシAIを実装した話(FL実験2019)
理学部情報科学科の関数論理型言語プログラミング実験の最終課題でリバーシAIを実装したので過程のメモです
とりあえず僕が提出したものはここにあげてます。
github.com
言語は関数論理型なら相談すれば許可されるようでしたが僕は諸々のインターフェースが提供されているOCamlで実装しました。
Prologで実装する人を見てみたい...あとなぜか手続き型であるところのRustが許可されていました。
課題が締め切りの1ヶ月前に公開されたのですが余裕がなくて結局試験期間中に合間を縫ってやったのと試験後2日で仕上げました。
中盤終盤探索
nega-max,nega-alpha,nega-scout,MTD(f)の順くらいで実装しようかな〜とか思ってたんですが結局nega-alphaまでしかやりませんでした(怠惰)
とりあえずなにも考えずにnegamaxで終盤読み切りを書いて、その後nega-alphaに変えて枝刈りを入れました。
終盤10手読み切りその他ランダムでランダムに勝率8割くらいで思ったより低いなぁと感じたので適当な評価関数で終盤以外も4手読むようにすると100戦100勝になりました。
bitboard
与えられた雛形のボードの処理はとても重いので64bit整数2つ(各ビットが64マスに対応)のbitboardモジュールを書いてそれに切り替えました。
実装はオセロをビットボードで実装する - Qiitaが参考になると思います。
この時点でランダム性はないのでbitboardを導入しても変わるはずのないのですが、挙動が微妙に変わってしまったのでデバッグを試みたのですがこれに3日も溶かしてしまいました。
int64型の0x7f7f7f7f7f7f7f7fというmaskをつくるときに一番上のbitが立ってないのでof_int 0x7f7f7f7f7f7f7f7fと書いていたのですが、OCamlのintは63bit符号付き整数なので63bit目が立っている数は負の数を表しており、of_intでint64に変換すると符号拡張されて0xff7f7f7f7f7f7f7fになってしまうというカラクリでした。既存のボードを全関数の引数に加え直して内部で等しいか判定して違ったら例外を投げるようにして角がひっくり返る現象を発見したときはマスオさんばりにえぇ〜っ!?となりました。
序盤
適当な評価関数で序盤も手を決めていたのでこれではいくら終盤を強くしてもそのうち限界がくるだろうと思ったので定石を入れました。いろいろ調べてみるとlogistello,edax,WZebraあたりの定石があってこの中でもedaxのが一番強そうだったのですが、bookの構造が結構複雑だったので諦めてlogistelloのopening bookをハッシュテーブルにいれるようにしました
終盤探索再考
nega-scoutを実装しようかなとか想いつつ関数型で実装しにくい形してるなぁと思ってダラダラchess programming wikiを読み漁っているとalpha-betaの枝刈りはmove ordering(次にどのノードをdfsするかの順序付け)によって刈られる量が劇的に変わる(少し考えればそれはそう)とあったのでmove orderingに力をいれることを決意しました。とりあえず相手の有効手を減らす手から探索するように変えるとめっちゃ早くなって探索可能手数が5手くらい伸びました。その他にオーバーヘッドは増えるが2~3手の浅めの探索をしてその評価値の高い順に探索する方法や、深さkの探索の評価値の順を用いて深さk+1の探索をやる、を繰り返す反復深化(ID-DFS)があって、反復深化が早そうと思ったので実装してみました。しかしそんなに早くなくて、原因を突き止める時間も気力も残ってなかったので潔く捨ててもとのorderingに戻しました。
ここまで終盤読み切りで勝ちの時は石差が最大になるような手を選ぶようになっていましたが、一つでも勝ちルートを見つければそっちに突っ走ればいいのでそれを選択するように変えました。そうすると勝ちの場合にかなり早く探索が終わることが結構ありました。ここまでは終盤読み切りは残り18マスになってからでその前までは中盤探索、というように明確に分けていたのですが上の改善を利用するために残り19~22マスのときにも5000000ノードに限定して勝ちルート探索(超えたら例外を投げてplay内で捕捉して中盤探索に切り替え)するように変えました。akouryyやgasinさんとの対戦ではこれが結構効果があるようでした(数回に一回くらい20,21手で勝ちルートが見つかっていた印象)。
でもこの改善によって自分のAIがかなり有利な状況でも33-31で勝つようないやらしいプレーをするようになって少し悲しかったです。
本番の環境が自分の学科PCと同等かそれ以上である保証がないので、本当は制限は時間で設けるべきなのですがこれをサボったので変に切れ負けしないかどうかが心配...(一応学科PCで20秒くらいは残るようにしているけど)。
nega-scoutにするか〜と思ったけど時間がなかったので諦めました、評価関数もはじめの適当なやつのままですがそんなに弱くもなかったので妥協しました。
対戦成績
提出verとgasinさんのOCalloを100戦させると50勝40敗10分けでした。
まとめ
競プロで枝刈り探索は最悪ケースが読めないし通ったり通らなかったりするのであまり好きではなかったのですが、オセロの探索の高速化は結構楽しかったです(結局序盤はopening book拾ってきただけ、一番つらそうな評価関数のチューニングからは逃げてしまいましたが)
19er内での順位が気になるところですがひとまず忘れようと思います
(終盤24手読み切ってると言っていたkamiが何をしたのかとても気になって仕方ない...)
2020/1/9 追記
ようやくリバーシの対戦結果が後悔され、結果は93勝231敗で24位/28人中、レポートは過去最低点を記録しました。(本番環境は学科PCよりも低スペックだったようです)
弱すぎて泣きました。
19er内でいい順位とりたかっただけに残念です
ちゃんと時間はかってチューニングしましょう
20erの方の参考になれば幸いです。
AOJ 2642 Dinner
自炊する日をの
日間(日は0-indexed)とし、
とおくと幸福度は
よってkを固定した時、P*i+C[i]が小さいものから順にk個選ぶのが最適。
ちゃんと定式化するの大事…
ll N,P,Q; ll C[500100]; vector<ll> vec; int main(){ scanf("%lld %lld %lld",&N,&P,&Q); ll sum = 0; for(int i=0;i<N;i++){ scanf("%lld",&C[i]); sum += C[i]; vec.pb(P*i+C[i]); } sort(all(vec)); for(int i=1;i<vec.size();i++)vec[i]+=vec[i-1]; ll ans = sum; for(int i=1;i<=N;i++)chmax(ans,sum+i*P*Q+P*i*(i-1)-vec[i-1]); cout << ans << endl; return 0; }